Регулярные выражения в PowerShell
[!ПРИМЕЧАНИЕ] Эта статья покажет вам синтаксис и методы использования регулярных выражений в PowerShell, в ней обсуждается не весь синтаксис. Более полную информацию о регулярных выражениях вы сможете найти в статьях:
- Регулярные выражения и команда grep
- Команда grep: опции, регулярные выражения и примеры использования
Регулярное выражение — это шаблон, используемый для поиска совпадений в тексте. Оно может состоять из буквальных символов, операторов и других конструкций.
В этой статье демонстрируется синтаксис регулярных выражений в PowerShell. PowerShell имеет несколько операторов и командлетов, использующих регулярные выражения. Вы можете узнать больше об их синтаксисе и использовании по ссылкам ниже.
- Select-String
- - Операторы -match и -replace
- -split
- выражение switch с опцией -regex
Регулярные выражения PowerShell по умолчанию не чувствительны к регистру. У каждого метода, показанного выше, есть свой способ принудительного учёта регистра.
| Метод | Чувствительность к регистру |
|---|---|
| Select-String | Используйте переключатель -CaseSensitive |
| Выражение switch | Используйте опцию -casesensitive |
| Операторы | Префикс с 'C' (-cmatch, -csplit, или -creplace) |
Символьные литералы
Регулярное выражение может быть буквальным символом или строкой. Текст считается совпавшим с регулярным выражением, если в нём встречается точное вхождение указанной последовательности символов.
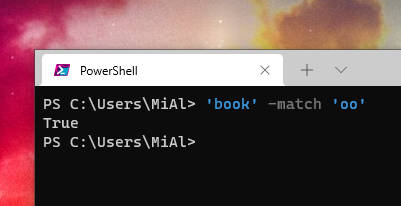
Этот оператор возвращает истину, потому что «book» содержит строку «oo»:
'book' -match 'oo'
Классы символов
В то время как символьные литералы работают, если вы знаете точный шаблон, символьные классы позволяют вам быть менее конкретными.
Группы символов
[группа символов] позволяет вам сопоставить любое количество символов на одной позиции, в то время как [^группа символов] соответствует только символам, НЕ входящим в группу.
Следующее выражение вернёт истину, если шаблон найдёт big, bog или bug.
'big' -match 'b[iou]g'

Если ваш список символов для сопоставления включает символ дефиса (-), он должен быть в начале или в конце списка, чтобы отличить его от выражения диапазона символов.
Диапазоны символов
В качестве части шаблона также можно указать диапазон набора символов. Символы могут быть буквенными [A-Z], числовыми [0-9] или даже основанными на ASCII [ -~] (все печатные символы).
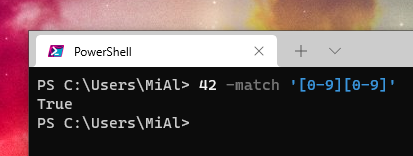
Выражение вернёт истину, поскольку шаблон соответствует любому двухзначному числу:
42 -match '[0-9][0-9]'
Числа
У некоторых часто используемых диапазонов есть свои собственные обозначения. Обозначение \d соответствует любой десятичной цифре. И наоборот, \D соответствует любой не десятичной цифре.
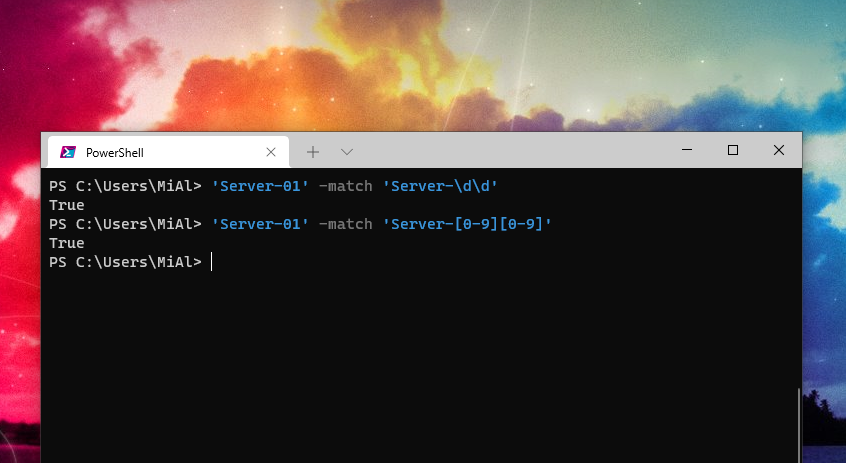
Это выражение соответствует именам в диапазоне Server-01 — Server-99, поэтому выражение вернёт истину:
'Server-01' -match 'Server-\d\d'
Следующая запись по значению идентична предыдущей:
'Server-01' -match 'Server-[0-9][0-9]'
Обозначение слова
Класс символов \w обозначает слово [a-zA-Z_0-9], то есть это любая последовательность из букв, цифр и нижнего подчёркивания. Для обозначения не-слова используется \W.
Это выражение вернёт истину. Этот шаблон (регулярное выражение) совпадёт с первым символом «B»:
'Book' -match '\w'
Найденные совпадения сохраняются в переменную $Matches, поэтому вы можете проверять, какая именно строка совпала с регулярным выражением:
'Server-01' -match '\w' $Matches 'Server-01' -match '\W' $Matches

Подстановочные знаки
Точка (.) – это подстановочный знак в регулярных выражениях. Она будет соответствовать любому одному символу, кроме новой строки (\n).
Это выражение возвращает истину. Шаблон соответствует любым 4 символам, кроме символа новой строки.
'a1\ ' -match '....'
Белый пробел
Белый пробел (соответствует пробелу, вертикальному и горизонтальному Tab, символу Newline и некоторым другим аналогичным символам) обозначается как \s. Любой непробельный символ обозначается как \S. Также можно использовать буквальные символы пробела ' '.
Это выражение возвращает истину. В шаблоне используются оба метода для сопоставления пробела (условное обозначение класса символов и буквальный пробел):
' - ' -match '\s- '
Квантификаторы
Квантификаторы контролируют, сколько экземпляров каждого элемента должно присутствовать во входной строке.
Ниже приведены некоторые из квантификаторов, доступных в PowerShell:
| Квантификатор | Описание |
|---|---|
| * | Ноль или более раз. |
| + | Один или более раз. |
| ? | Ноль или один раз. |
| {n,m} | По меньшей мере n, но не более чем m раз. |
Звёздочка (*) соответствует предыдущему элементу ноль или более раз. В результате совпадением будет даже для пустой строки.
Следующее выражение возвращает истину для всех строк имени учётной записи, даже если имя отсутствует.
'ACCOUNT NAME: Administrator' -match 'ACCOUNT NAME:\s*\w*'
Знак плюс (+) соответствует предыдущему элементу один или несколько раз.
Следующее выражение возвращает истину, поскольку введённое имя соответствует шаблону: имя начинается с одной или более заглавной буквы, затем идёт дефис, затем две цифры.
'DC-01' -match '[A-Z]+-\d\d'
Знак вопроса (?) соответствует предыдущему элементу ноль или один раз. Как и звёздочка *, он будет соответствовать даже строкам, в которых отсутствует элемент.
Следующее выражение возвращает истину, поскольку введённое имя соответствует шаблону: имя начинается с одной или более заглавной буквы, затем идёт дефис, который может и отсутствовать, затем две цифры.
'SERVER01' -match '[A-Z]+-?\d\d'
Квантификатор {n, m} может использоваться несколькими различными способами для обеспечения детального контроля над количеством. Второй элемент m и запятая необязательны.
| Квантификатор | Описание |
|---|---|
| {n} | Совпадение ТОЧНО n число раз. |
| {n,} | Совпадение ПО КРАЙНЕЙ МЕРЕ n число раз. |
| {n,m} | Совпадение между n и m числом раз. |
Следующий шаблон означает: цифра ровно три раза, затем дефис, затем цифра ровно три раза, затем дефис, затем цифра ровно четыре раза:
'111-222-3333' -match '\d{3}-\d{3}-\d{4}'
Якоря (анкоры)
Якоря указывают на начало и конец строки.
Два обычно используемых якоря — это «^» и «$.» Каретка (^) соответствует началу строки, а знак доллара ($) соответствует концу строки. Якоря позволяют сопоставить текст в определённой позиции, а также отбросить ненужные символы.
Шаблон в следующем примере предполагает, что за буквой h будет стоять конец слова. Это выражение вернёт ЛОЖЬ.
'fishing' -match '^fish$'
[!ПРИМЕЧАНИЕ] При определении регулярного выражения, содержащего привязку $, обязательно заключите регулярное выражение в одинарные кавычки (') вместо двойных кавычек ("), иначе PowerShell будет трактовать выражение как переменную.
При использовании якорей в PowerShell вы должны понимать разницу между параметрами регулярных выражений SINGLELINE и MULTILINE.
- MULTILINE: в многострочном режиме символы ^ и $ должны совпадать с началом и концом каждой СТРОКИ, а не с началом и концом входной строки.
- SINGLELINE: однострочный режим обрабатывает входную строку как ЕДИНУЮ СТРОКУ. Это заставляет символ точки (.) соответствия каждому символу (включая символы новой строки) вместо поведения по умолчанию, которое заключается в следующем: точка соответствует любому символу, ЗА ИСКЛЮЧЕНИЕМ новой строки \n.
Экранирование специальных символов
Обратная косая черта (\) используется для экранирования символов, при её использовании специальные символы в регулярном выражении начинают трактоваться как буквальные символы.
Следующие символы зарезервированы и имеют специальное значение в шаблоне регулярного выражения: []().\^$|?*+{}
Вам нужно будет экранировать эти символы в ваших шаблонах, если вы хотите, чтобы они искались во входящих данных как буквальные символы.
Следующее выражение возвращает истину и соответствует числам с точностью не менее 2 цифр. Десятичная точка экранируется с помощью обратной косой черты, то есть при такой записи точка больше не означает «любой символ», экранированная точка означает «буквальная точка».
'3.141' -match '3\.\d{2,}'
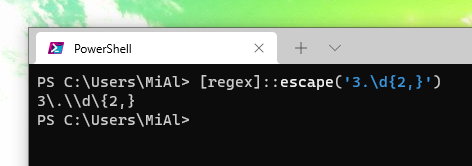
Существует статический метод класса регулярных выражений, который может экранировать текст за вас.
[regex]::escape('3.\d{2,}')
Будет выведено регулярное выражение с экранированными специальными символами:
3\.\\d\{2,}
[!ПРИМЕЧАНИЕ] Этот метод экранирует все зарезервированные символы регулярных выражений, включая присутствующие обратные косые черты, используемые в классах символов. Обязательно используйте его только на той части шаблона, которую вам нужно экранировать.
Обратите внимание, что этот метод сработал странно: экранировал точку, затем экранировал косую черту, являющуюся частью обозначения класса цифры (\d), затем, почему-то, экранировал одну фигурную скобу, но не экранировал другую. В общем, лучше не использовать этот метод.
Экранирование других символов
Существуют также зарезервированные escape-символы, которые можно использовать для соответствия специальным типам символов.
Ниже приведены несколько наиболее часто используемых escape-символов:
| Экранированный символ | Описание |
|---|---|
| \t | Соответствует tab |
| \n | Соответствует newline |
| \r | Соответствует возврату каретки (carriage return) |
Группы, захваты и подстановки
Конструкции группирования разделяют входную строку на подстроки, которые можно использовать в этом же регулярном выражении или игнорировать. Сгруппированные подстроки называются подвыражениями. По умолчанию подвыражения записываются в пронумерованные группы, хотя вы также можете присвоить им имена.
Группирующая конструкция — это регулярное выражение, заключённое в круглые скобки. Любой текст, совпадающий с заключённым в него регулярным выражением, захватывается. В следующем примере вводимый текст разбивается на две группы захвата.
'The last logged on user was CONTOSO\jsmith' -match '(.+was )(.+)' True
Используйте автоматическую переменную $Matches для получения захваченного текста. Текст, представляющий всё совпадение, сохраняется под ключом 0.
$Matches.0 The last logged on user was CONTOSO\jsmith
Захваты сохраняются в числовых ключах INTEGER, которые увеличиваются слева направо. Захват 1 содержит весь текст до имени пользователя, захват 2 содержит только имя пользователя.
$Matches
Name Value
---- -----
2 CONTOSO\jsmith
1 The last logged on user was
0 The last logged on user was CONTOSO\jsmith
[!ВАЖНО] Ключ 0 — это ЦЕЛОЕ число. Вы можете использовать любой метод HASHTABLE для доступа к сохранённому значению.
'Good Dog' -match 'Dog' True $Matches[0] Dog $Matches.Item(0) Dog $Matches.0 Dog
Именованные захваты
По умолчанию захваты хранятся в возрастающем числовом порядке слева направо. Вы также можете назначить ИМЯ группе захвата. Это ИМЯ становится ключом в автоматической переменной $Matches.
Внутри группы захвата используйте ?<keyname> для хранения захваченных данных под именованным ключом.
$string = 'The last logged on user was CONTOSO\jsmith'
$string -match 'was (?<domain>.+)\\(?<user>.+)'
True
$Matches
Name Value
---- -----
domain CONTOSO
user jsmith
0 was CONTOSO\jsmith
$Matches.domain
CONTOSO
$Matches.user
jsmith
В следующем примере сохраняется последняя запись журнала в журнале безопасности Windows. Предоставленное регулярное выражение извлекает имя пользователя и домен из сообщения и сохраняет их под ключами: N для имени и D для домена.
$log = (Get-WinEvent -LogName Security -MaxEvents 1).message
$r = '(?s).*Account Name:\s*(?<N>.*).*Account Domain:\s*(?<D>[A-Z,0-9]*)'
$log -match $r
True
$Matches
Name Value
---- -----
D CONTOSO
N jsmith
0 A process has exited....
Подстановки в регулярных выражениях
Использование регулярных выражений с оператором -replace позволяет динамически заменять текст с помощью захваченного текста.
ВВОД -replace ОРИГИНАЛ, ПОДСТАНОВКА
Здесь:
- ВВОД: строка по которой выполняется поиск
- ОРИГИНАЛ: регулярное выражение, используемое для поиска входной строки.
- ПОДСТАНОВКА: выражение подстановки для замены совпадения, найденные во входной строке.
[! ПРИМЕЧАНИЕ] Операнды ОРИГИНАЛ и ПОДСТАНОВКА подчиняются правилам обработчика регулярных выражений, таким как экранирование символов.
На группы захвата можно ссылаться в строке ПОДСТАНОВКА. Замена выполняется с помощью символа $ перед идентификатором группы.
Два способа ссылаться на группы захвата – по НОМЕРУ и по ИМЕНИ.
- По НОМЕРУ - Группы захвата нумеруются слева направо.
'John D. Smith' -replace '(\w+) (\w+)\. (\w+)', '$1.$2.$3@contoso.com' John.D.Smith@contoso.com
- По ИМЕНИ — На группы захвата также можно ссылаться по имени.
'CONTOSO\Administrator' -replace '\w+\\(?<user>\w+)', 'FABRIKAM\${user}'
FABRIKAM\Administrator
Выражение $& представляет весь совпавший текст:
'Gobble' -replace 'Gobble', '$& $&' Gobble Gobble
[!ПРЕДУПРЕЖДЕНИЕ] Поскольку символ $ имеет специальное значение, вам нужно использовать строки с одинарными кавычками, либо экранировать символ $ при использовании двойных кавычек.
'Hello World' -replace '(\w+) \w+', '$1 Universe' Hello Universe "Hello World" -replace "(\w+) \w+", "`$1 Universe" Hello Universe
Кроме того, если вы хотите использовать символ $ в качестве буквального символа, используйте $$ вместо обычных escape-символов. При использовании двойных кавычек всё равно экранируйте все экземпляры $, чтобы избежать неправильной трактовки.
'5.72' -replace '(.+)', '$$$1' $5.72 "5.72" -replace "(.+)", "`$`$`$1" $5.72